C语言基础-嵌入式面试
1. C和C++区别:
- C语言:面向过程的语言,其核心关注于问题是如何被解决的,把实现一个软件功能的过程分为一个个过程。 例如汽车要去加油,其过程为:汽车启动->汽车行驶->汽车加油。在这里我们不关注物件本身(汽车这个对象),默认定义执行该过程的主题是汽车。
- C++语言: 面向对象的语言,在计算机科学中的对象既可以表示客观世界的问题空间(namespace)中的具体的某个事物,又可以表示软件系统解空间的基本元素,如变量、数据结构、函数等。例如汽车要去加油,汽车<启动,开车,加油>, 我们关注物件(对象)本身,只需要考虑什么时间干什么事。启动,开车,加油属于这个物件的基本属性。
C语言基础部分:
- 标识符: 一个标识符以字母或者下划线开始的后面可以跟多个字母、数字、下划线。C标识符中不允许出现标点字符,并且区分大小写。
- 关键字: C中的保留字,这些保留字不能作为常量名,变量名和其他标识符的名称。常用的的关键字包括:while, do, for, break, continue, default, goto, char, double, int, long, short, float,
| 关键字 | 说明 |
|---|---|
| auto | 声明自动变量 |
| const | 定义常量,如果一个变量可以被const修饰,那么它的值就不能被在改变 |
| enum | 声明枚举类型 |
| extern | 声明变量或函数是在其他文件或本文件其他位置定义 |
| register | 声明寄存器变量 |
| sizeof | 计算数据类型或变量长度(即所占的字节数) |
| static | 声明静态变量 |
| typeof | 给数据类型取别名 |
| union | 声明共用体类型 |
| void | 声明函数无返回值或者无参数,声明无类型指针 |
| volatile | 说明变量在程序执行中可以被隐含的改变 |
- **数据类型: ** C语言有四种数据类型:
- **基本数据类型: **他们是算术类型,包括整数类型和浮点类型,注意char是属于整数类型的。 基本数据类型占用的空间(64位机器):char-1字节,int-4字节, float-4字节,double-8字节。
- 枚举类型: 他们也是算术类型,被用来定义在程序中,只能赋予其一定的离散整数值的变量
- void类型: 类型说明符 void表明没有可用的值
- 派生类型: 它们主要包括:指针,数组,结构,共用体,和函数类型
- 强制类型转换: (类型说明符)(表达式)
变量:
变量是程序可操作的存储区名称。全局变量保存在内存的全局存储区中,占用静态的存储单元;局部变量保存在栈中,只有在所在函数被调用的时候才动态地为变量分配存储单元。
C语言经过编译后将内存分为一下几个区域:
- 栈(stack): 由编译器进行管理,自动分配和释放,存放函数调用过程的各种参数,局部变量,返回值以及函数的返回地址。操作方式类似于数据中的栈。
- 堆(heap): 用于程序动态申请分配和释放空间。C语言中的malloc和free,C++中的new和delete均是在堆中进行的。正常情况下,程序员申请的空间在使用结束后应该释放,若程序员没有释放空间,则在程序结束后由系统自动回收。注意:这里的对并不是数据结构中的堆。
- 全局(静态)存储区: 分为DATA和BSS段,DATA段(全局初始化区)存放初始化的全局变量和静态变量;BSS段(全局未初始化分区) 存放未初始化的全局变量和静态变量。程序运行结束时自动释放,其中在BSS段在程序执行之前会被系统自动清零,所以未初始化的全局变量和静态变量在程序执行之前已经为0.
- 文字常量区:存放常量字符串,程序结束由系统释放。
- 程序代码区:存放程序的二进制代码。
因此,C语言的全局变量和局部变量在内存之中是有区别的,C语言的全局变量包括外部变量和静态变量,均是保存在全局存储区中,占用永久性的存储单元;局部变量,即自动变量,保存在栈中,只有在所在的函数被调用时才有系统动态在栈中分配临时性的存储单元。
1 | #include <stdio.h> |
常量
常量是固定值,在程序的执行期间不会改变。它可以是任意基本的数据类型,整数常量,浮点常量,字符常量,枚举常量等。
- 定义常量: 定义常量有两种方法,使用#define或者使用const关键字,这两种方法从本质上是不同的。#define 是宏定义,它不能定义常量,但宏定义可以实现在字面意义上和其它定义常量相同的功能,本质的区别就在于 #define 不为宏名分配内存,而 const 也不为常量分配内存,怎么回事呢,其实 const 并不是去定义一个常量,而是去改变一个变量的存储类,把该变量所占的内存变为只读!
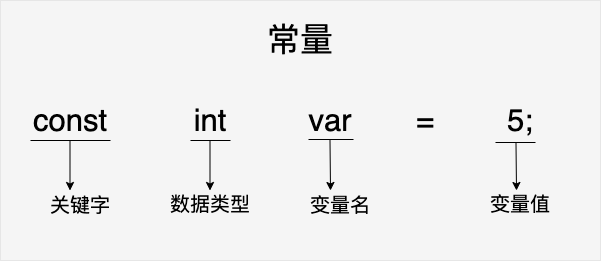
示例
#define length 10
#define NEWLINE ‘\n’
const int var=5; - 整数常量:整数常量可以是十进制,八进制,十六进制的常量,前缀指定基数,0x/0X表示十六进制,0表示八进制,不带前缀默认代表十进制。整数常量也可以带一个后缀,U代表无符号整数, L代表长整数,大小写和顺序任意。
C++语言的三大特性
- 封装: C++语言支持数据封装,类是数据封装的工具,对象是数据封装的实现,在封装中,还提供一种对数据访问控制的机制,是的一些数据隐藏在封装体内,具有隐藏性。封装和外接的信息交换是通过操作接口进行的,这种访问的控制机制体现在类的共有成员(public),私有成员(private),和保护成员(protected)上。私有成员只有类内说明的一些函数才能访问;共有成员类外的函数也可以访问,保护成员只有该类的成员函数和派生类才能访问。
- 继承: C++语言允许单继承和多继承。一个类可以根据需要生成它的派生类,派生类还可以再生成派生类。派生类可以继承基类的成员同时也可以定义自己的成员。继承是实现数据抽象和共享的一种机制。该机制可以避免不能重复利用程序导致的资源浪费。
- 多态: 多态指的是对不同类发出的相同消息会有不同的实现。多态性也可以理解为,在一般类中定义的属性和服务被特殊类继承后,可以具有不同的数据类型或不同的实现。简单来说,多态性指的是发出同样的消息被不同的数据类型的对象接收后会导致不同的行为。C++支持多态性主要表现在:C++语言允许函数重载和运算符重载;C++语言通过定义虚函数来支持动态联编。多态特性的工作依赖虚函数的定义,在需要解决多态问题的重载成员函数前,加上virtual关键字,那么该成员函数就变成了虚函数,从上例代码运行的结果看,系统成功的分辨出了对象的真实类型,成功的调用了各自的重载成员函数。