Linux文件系统
本文用于介绍Linux的文件系统
本文用于整理Hexo icarus主题的常见配置。
本文用于总结Bash相关的基本内容。
FreeRTOS是一个迷你的实时操作系统内核。作为一个轻量级的操作系统,功能包括:任务管理、时间管理、信号量、消息队列、内存管理、记录功能、软件定时器、协程等,可基本满足较小系统的需要。
FreeRTOS是为小型嵌入式系统设计的可裁剪实时内核。其主要特点有:
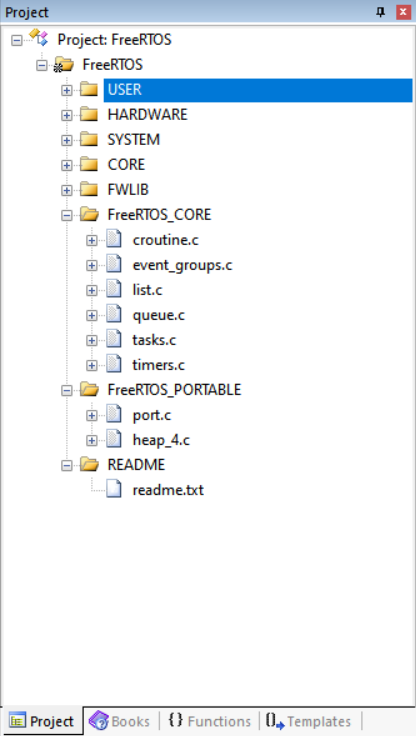
在FreeRTOS v9.0版本中,FreeRTOS的代码主要包含两个文件夹:FreeRTOS_CORE和FreeRTOS_PORTABLE。这两个文件夹下包含多个.C文件。
裸机编程中,一个复杂的功能通常需要多个子函数来实现,不同的子函数之间的通常采用一些全局变量来实现联系。在RTOS中,我们不仅可以使用全局变量,还可以采用系统自带的任务间通信机制。这种机制更加受推荐。其原因是:
FreeRTOS任务间的通信方式:
在实际应用中,一个任务或中断服务函数经常需要和另一个任务进行消息传递。裸机情况下通常通过全局变量实现。但是操作系统使用全局变量的方式会涉及“资源管理”问题。FreeRTOS中采用队列机制完成任务与任务,和任务与中断之间的消息传递。 队列可以存储有限的,大小固定的数据项目。
FreeRTOS创建任务、队列、信号量有两种方法:
第一种是由用户自行定义所需的RAM,这种方法也叫静态的方法。静态方法的函数一般由Static结尾,比如任务创建 xTaskCreateStatic()。 使用此函数创建任务的时候需要用户定义任务堆栈。
另一种是动态的申请所需的RAM,使用动态内存管理时,FreeRTOS内核在创建任务、队列、信号量的时候会动态的申请RAM。C语言标准库的malloc()和free()也可以实现动态内存管理,但这种方法在小型嵌入式系统中效率不高,会占用很多代码空间,并且他们的线程不是安全的,程序执行的时间也是不确定的,此外还会导致内存碎片。因此在FreeRTOS中,内核采用 pvPortMalloc()代替 malloc() 申请内存,采用 vPortFree()函数释放内存。关于内存分配,FreeRTOS提供了5这种内存分配的方法: 也就是在5个.c文件,heap_1.c, heap_2.c, heap_3.c, heap_4.c, heap_5.c。
内存碎片:
内存分配与管理的方法中需要解决的问题之一就是内存碎片,其产生过程如下图所示,一个新的内存堆被系统按照应用需求分成多个大小不同的内存块。应用在使用完内存后就会进行释放,同时新的应用产生也需要分配新的可用该内存。经过多次申请和释放后,内存块被不断地分割,导致内存中存在大量的很小的内存块。这些内存块太小导致大多数应用无法使用,因此就形成了内存碎片。这些内存碎片的不断增加会导致实际可用内存越来越少。最终应用程序因为分配不到合适的内存而崩溃。而FreeRTOS的heap_4.c就提供了一个解决内存碎片的方法,即将内存碎片进行合并组成一个新的可用的大内存块。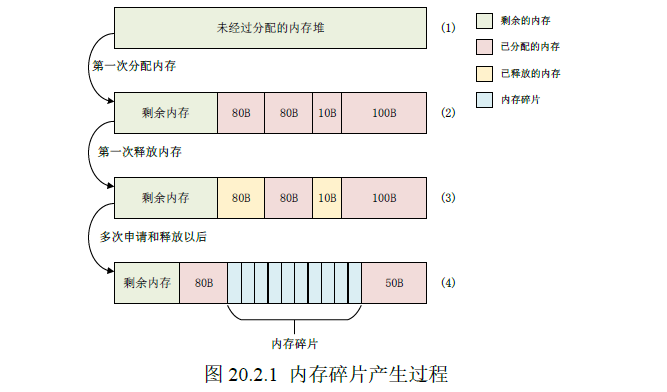
heap_1.c简介
动态内存分配需要一个内存堆,在FreeRTOS中的内存堆为ucHeap[],大小为configTOTAL_HEAP_SIZE.
heap_1特性如下:
heap_2.c简介
heap_3.c简介
heap_4.c简介
heap_4提供了一个最优的内存分配方法,不像heap_2, heap_4会将内存中的碎片合并成一个大的可用内存块,他提供了内存合并算法。内存堆为ucHeap[], 大小同样为configTOTAL_HEAP_SIZE。可以通过函数xPortGetFreeHeapSize()获取剩余内存大小。
heap_4特性如下:
heap_5简介
heap_5使用了heap_4相同的合并算法,内存管理实现基本相同,但是heap_5允许内存堆跨越多个不连续的内存段。如果使用heap_5需要调用函数xPortDefineHeapRegions()来对内存堆做初始化处理,该函数执行完之前禁止调用任何会调用pvPortMalloc()的函数。
参考资料:
[1] FreeRTOS源码探析之——任务调度相关
操作系统:操作系统是一个用以提供基础计算机功能的计算机程序,它可以向其他程序提供服务,应用来实现用户想要实现的功能。操作系统对应用程序的支持使得开发者在在开发应用程序是更加快捷,简单,易维护。
RTOS:大部分操作系统允许多个应用程序同时执行,这种成为多任务。但实际上,在任何一个时间点上只有一个进程在独立执行。由于应用程序切换足够快,好像所有的程序同时执行。操作系统中有一个调度器(Scheduler)的部分负责调度应用程序,决定什么时候执行哪个应用程序,调度器在每个程序之间的切换需要足够快速。实时操作系统费的调度器设计成可以提供确定的执行模式。实时性意味着嵌入式系统对某个具体事件的响应必须严格控制在一个预定的deadline内。实时操作系统会按照排序运行、管理系统资源,并为开发应用程序提供一致的基础。实时操作系统与一般的操作系统相比,最大的特色就是“实时性”,如果有一个任务需要执行,实时操作系统会马上(在较短时间内)执行该任务,不会有较长的延时。这种特性保证了各个任务的及时执行。
线程:线程是操作系统能够进行运算调度的最小单位,包含在进程中,是进程的实际运作单位。一条线程是进程中的一个单一控制流。线程有四枣红基本状态:产生,阻塞,非阻塞,结束。
进程:指计算机已运行的程序,是分时系统的基本运作单位。进程是程序的真正运行实例。进程有五种状态:新生,运行,等待,就绪,结束。在单CPU系统中,任何时间可能有多个进程在等待,但必定仅有一个进程在运行。
线程和进程区别:进程是资源分配的最小单位,线程是CPU调度的最小单位。进程和线程都是一个时间段的描述,是CPU工作时间段的描述,是运行中程序指令的描述。
实时操作系统的设计原则:
实时性: 实时性也叫实时计算(real-time computing), 实时约束指的是从事件发生到系统回应之间的最长时间限制。实时程序必须保证在严格时间限制内响应。 换句话说就是,任务(Task)必须在给定的时间(Deadline)内完成。比如汽车安全气囊响应,在汽车检测到撞击后,汽车ECU以及执行器需要在40ms内完全打开气囊,否则就会对乘客安全造成威胁。这个时候就要求汽车ECU的程序运行满足实时性标准。
硬实时: The firm real-time definition allows for infrequently missed deadlines. In these applications the system can survive task failures so long as they are adequately spaced, however the value of the task’s completion drops to zero or becomes impossible.
软实时: The soft real-time definition allows for frequently missed deadlines, and as long as tasks are timely executed their results continue to have value. Completed tasks may have increasing value up to the deadline and decreasing value past it.
区别: 硬实时操作系统必须使任务在确定的时间内完成;软实时操作系统能使绝大多数的任务在确定时间内完成。因此,硬实时和软实时的差别是,软实时只能提供统计意义上的实时。只要任务及时执行就会具有价值,如果任务超出Deadline,只会导致价值的稍微降低。如计算机的声音系统就是软实时的任务。 而硬实时任务只要超时,任务的价值就会降低到零。
调度同来确定多任务环境下任务执行的顺序和获得CPU资源后能执行的时间长度。操作系统通过一个调度程序来实现调度功能。调度程序以函数的形式存在,用来实现操作系统的调度算法。调度程序本身并不是一个任务,是一个函数调用,可在内核的各个部分进行调用。调用调度程序的具体位置成为一个调度点(Scheduling point), 调度点通常处于一下位置:**(i)** 中断服务程序的结束位置;**(ii)** 任务因等待资源而处于等待状态;**(iii)** 任务处于就绪状态时。
在操作系统中,一个任务有三种典型状态:
由于CPU在某个事件只能执行一个任务,因此大部分任务在多数事件处于阻塞或待命状态。可能大量的项目在待命列表里等待执行。这取决于系统所需的任务数量和调度器类型。通常情况下,简单的时间触发式调度器,待命任务列表的数据结构要尽可能缩短最坏情况下,程序在调度器关键部分的执行时间,防止其他任务一直在待命列表中无法及时执行。在这种调度器中,应该尽量避免抢占式任务,甚至应该关闭调度器之外的所有中断。并且待命列表的数据结构应该根据系统所需要最大任务数量进行优化。如果列表任务较多,双向链表是一个合适的结构。在任务列表的排序上,应该按照优先级对任务进行排序。这样可以保证高优先级任务的及时执行。
调度算法:
实时操作系统需要采用各种算法和策略保证系统行为的可预测性,并且调用一切可利用的资源完成实时控制任务。 其实时调度算法分为三种类别:基于优先级的调度算法(Priority-driven scheduling-PD),基于CPU使用比例的共享式调度算法(Share-drivescheduling-SD),基于时间进程的调度算法(Time—driven schedulinq-TD)。
基于优先级的调度算法给每个进程分配一个优先级,在每次进程调度的时候,最高优先级任务首先被执行。算法的类型分为两种:
静态调度:静态调度在系统开始运行前进行调度,严格的静态调度在系统运行时无法对任务重新调度。静态调度的目标是把任务分配给各个处理机,并对每一处立即给出所要运行的静态运行顺序。静态调度算法实现简单
死锁: 死锁是指一组进程中的各个进程均占有不会释放的资源,但因互相申请被其他进程所占用的不会释放的资源而处于的一种永久等待的状态。
死锁的四个条件:
互斥锁: 互斥锁是一种独占锁,当线程A加锁成功后,此时的互斥锁已经被线程A独占了,只要A没有释放受众的锁,线程B加锁就会失败,于是就是会释放CPU让给其他线程,既然B释放了CPU,也就意味着线程B的加锁代码会被阻塞。对于互斥锁加锁失败而阻塞的现象,是由操作系统内核实现的。
自旋锁: 自旋锁是一种特殊的互斥锁,当资源被加锁后,其他线程想要再次加锁,此时该线程不会被阻塞睡眠而是陷入循环等待状态(CPU不能做其他事情),循环检查资源持有者是否已经释放了资源,这样做的好处是减少了线程从睡眠到唤醒的资源消耗,但是会一直占用CPU资源。适用于资源的锁被持有时间段,而又不希望在线程的唤醒上花费太多资源的情况。
[1] https://blog.csdn.net/u012993936/article/details/41145863
[2] https://zhuanlan.zhihu.com/p/86861756
基本概念:
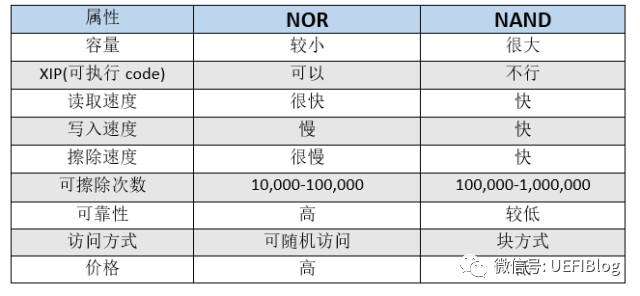
FLASH和EEPROM的最大区别是FLASH按扇区操作,EEPROM则按字节操作,二者寻址方法不同,存储单元的结构也不同,FLASH的电路结构较简单,同样容量占芯片面积较小,成本自然比EEPROM低,因而适合用作程序存储器,EEPROM则更多的用作非易失的数据存储器。
目前的单片机,RAM主要是做运行时数据存储器,FLASH主要是程序存储器,EEPROM主要是用以在程序运行保存一些需要掉电不丢失的数据.
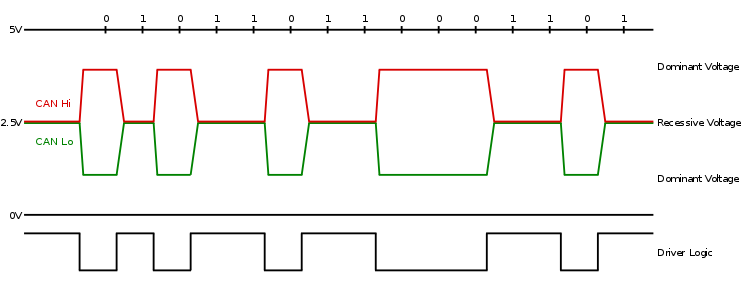
CAN总线协议是由博世开发的一种基于消息广播模式的串行通信总线,该协议非常适合于现场控制领域,主要用于实现汽车ECU之间的可靠通信。该通讯协议最高速率可达到1Mbps, 容错能力强。CAN控制器包含强大的检错和处理机制。另外CAN的节点之间不会传输大数据块,一帧CAN消息最多传输8字节用户数据。
总线特点
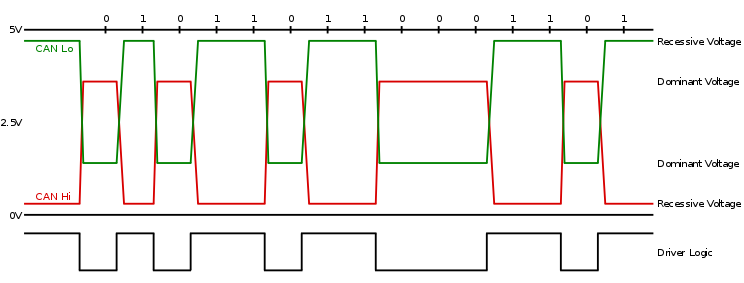
CAN报文帧结构:在CAN总线上,报文以“帧”的形式发送,每个报文帧包含以下部分:
CAN报文帧种类
(1)数据帧:由发送节点发出,包含0 - 8个数据字节。
(2)远程帧:发送远程帧向网络节点请求发送某一标识符的数据帧。
(3)错误帧:总线节点发现错误时,以错误帧的方式通知网络上的其他节点。
(4)过载帧:发送过载帧,表示当前节点不能处理后续的报文(如帧延迟等)。
SPI(Serial Peripheral interface)串行外围设备接口,该接口主要用在EEPROM,Flash,实时时钟,AD转化器,数字信号处理器和数字信号解码器之间。
DMA(Direct Memory Access),即直接存储器访问,DMA的传输方式可以无需CPU直接进行控制传输,也没有中断处理方式那样的保护现场和恢复现场的过程。通过硬件为RAM与I/O设备开辟一条直接传输数据的通路,可以使CPU的效率大为提高。
产生事件后,外设会向DMA控制器发送请求信号,DMA控制器根据通道优先级处理该请求,只要DMA控制器访问外设,DMA控制器就会向外设发送确认信号,外设获得确认信号后,便会立即释放请求。一旦外设使请求失效,DMA就会释放确认信号。如果有更多的请求,外设可以启动下一个事务。
| 关键字 | 说明 |
|---|---|
| auto | 声明自动变量 |
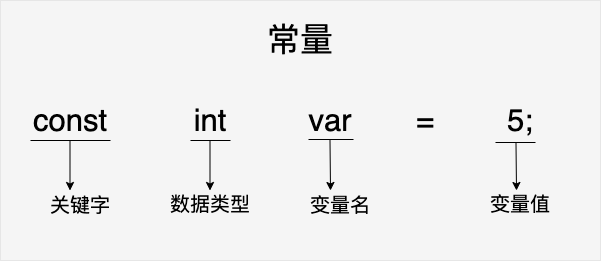
| const | 定义常量,如果一个变量可以被const修饰,那么它的值就不能被在改变 |
| enum | 声明枚举类型 |
| extern | 声明变量或函数是在其他文件或本文件其他位置定义 |
| register | 声明寄存器变量 |
| sizeof | 计算数据类型或变量长度(即所占的字节数) |
| static | 声明静态变量 |
| typeof | 给数据类型取别名 |
| union | 声明共用体类型 |
| void | 声明函数无返回值或者无参数,声明无类型指针 |
| volatile | 说明变量在程序执行中可以被隐含的改变 |
变量是程序可操作的存储区名称。全局变量保存在内存的全局存储区中,占用静态的存储单元;局部变量保存在栈中,只有在所在函数被调用的时候才动态地为变量分配存储单元。
C语言经过编译后将内存分为一下几个区域:
因此,C语言的全局变量和局部变量在内存之中是有区别的,C语言的全局变量包括外部变量和静态变量,均是保存在全局存储区中,占用永久性的存储单元;局部变量,即自动变量,保存在栈中,只有在所在的函数被调用时才有系统动态在栈中分配临时性的存储单元。
1 | #include <stdio.h> |
常量是固定值,在程序的执行期间不会改变。它可以是任意基本的数据类型,整数常量,浮点常量,字符常量,枚举常量等。
应用软件层最重要的就是SWC, 而SWC之间的通信需要接口,每个SWC由runnable组成,所以应用软件层的组成主要分为三个部分:

例子:汽车顶灯控制
汽车的顶灯一般有三种模式:常闭,常开,随着车的开关而开关的模式。实现汽车顶灯的控制需要传感器,处理单元和执行器。假设左右两个车门,左右两个车灯,一个开关传感器。该车顶的的控制需要7个SWC实现。但是这些SWC并非由一个ECU完成。
SWC之间的通信是通过虚拟功能总线(VFB)实现,该总线是片内外通信的结合体:

在实际的汽车中,上述的7个SWC将被分配到两个ECU中。车灯开关,调光控制器和左右顶灯由车身顶部的ECU控制;左右车门和车门开关逻辑单元由专用的车门ECU芯片控制。两个ECU即连个控制器,分别位于车身前部的车门控制器和车身顶部的顶灯控制器。ECU内部通信通过RTE进行管理,跨ECU通信通过外部CAN总线进行。

SWC的类型总共有三种:原子级SWC(Atomic SWC),集合级SWC(Composition SWC),特殊的SWC。
原子级SWC(Atomic SWC): 最小单元,不可再拆分,每个原子级SWC对应一个.c文件。比其更小的单元是runnable,即.c文件中的函数。每个SWC的功能基本上都是用来实现特定的算法。

集合级SWC(Composition SWC):该级别的SWC将很多功能相近或者需要整合到一处的Atomic SWC整合起来,方便SWC归类。

集合级SWC类似于一个文件夹,用于存放相近功能的Atomic SWC.

特殊SWC:在实际的工程中,不止应用层需要设计SWC, 在基础软件层中,IO硬件抽象成层和复杂驱动(CDD)都需要手动添加代码。他们被看做一种特殊的SWC进行操作。

Ports存在于SWC之间作为通信的通道。或者SWC通过RTE和BSW做接口通信使用。Ports共有五种类型,如下图所示:

S/R接口:用于传输数据。该数据传输过程通过RTE进行管理,避免数据出错。如同时调用同一数据可能出错。在数据传输时,一个接口可以包含多个数据,类似于通过结构体的传输。可以传输的数据类型包括基础的如int, float等,以及复杂数据类型如record, array等。

C/S接口:该接口的作用是提供操作,即Server提供函数供Client调用。调用的过程分为同步,异步两种。同步代表直接调用,相当于函数直接插入上下文运行;异步需要灯带,相当于函数在另一个线程中运行,不影响原线程运行。C/S接口的可以提供多个操作(函数),可在ECU内部或者跨ECU调用。

Runnable即SWC中的函数,在AutoSAR架构被DaVinci软件生成时,Runnable是空函数,需要手动添加代码实现相应功能。Runnable可以被触发,例如定时器触发,操作调用触发,以及接受数据触发等。

RTE是AutoSAR架构中介于应用层和基础软件层之间,是AutoSAR虚拟功能总线VFB的接口的实现。其目的是为应用软件的SWC之间的通信提供基础设施服务,并促进包括OS在内的基础软件组建的访问。
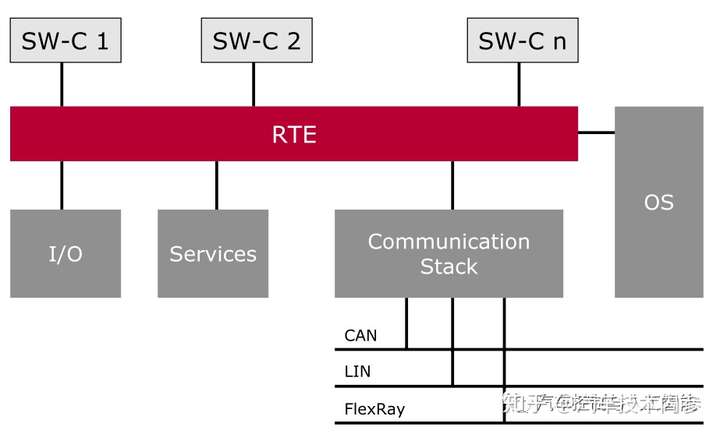
RTE在Vector的工具链中是自动生成的,它的作用包括:
下图是车顶的控制系统中SWC与RTE以及BSW的组件之间的关系。
RTE作为运行环境的主要功能有:

Runnables的触发条件
Runnables在设计时,需要考虑触发条件,负责无法运行。触发条件即一些特定的事件。AutoSAR中主要规定了以下触发事件:
RTE可以作为SWCs和BSW之间的交流途径:
R/S接口的实现
在配置好DaVinci后,RTE会自动生成一些调用,在runnable上方,可以直接复制。下面是一个例子:
/**********************************************************************************************************************
*
* Runnable Entity Name: RAB_Core0_100us
*
*---------------------------------------------------------------------------------------------------------------------
*
* Executed if at least one of the following trigger conditions occurred:
* - triggered on TimingEvent every 100us
*
**********************************************************************************************************************
*
* Input Interfaces:
* =================
* Explicit S/R API:
* -----------------
* Std_ReturnType Rte_Read_AppPI_Can_ReceiverCore0_DEP_Can_Receiver(Idt_Can_Receiver *data)
*
* Output Interfaces:
* ==================
* Explicit S/R API:
* -----------------
* Std_ReturnType Rte_Write_AppPI_Can_SenderCore0_DEP_Can_Sender(Idt_Can_Sender data, Rte_TransformerError *transformerError)
*
* Service Calls:
* ==============
* Service Invocation:
* -------------------
* Std_ReturnType Rte_Call_ComM_UserRequest_GetCurrentComMode(ComM_ModeType *ComMode)
* Synchronous Service Invocation. Timeout: None
* Returned Application Errors: RTE_E_ComM_UserRequest_E_NOT_OK
* Std_ReturnType Rte_Call_ComM_UserRequest_GetMaxComMode(ComM_ModeType *ComMode)
* Synchronous Service Invocation. Timeout: None
* Returned Application Errors: RTE_E_ComM_UserRequest_E_NOT_OK
* Std_ReturnType Rte_Call_ComM_UserRequest_GetRequestedComMode(ComM_ModeType *ComMode)
* Synchronous Service Invocation. Timeout: None
* Returned Application Errors: RTE_E_ComM_UserRequest_E_NOT_OK
* Std_ReturnType Rte_Call_ComM_UserRequest_RequestComMode(ComM_ModeType ComMode)
* Synchronous Service Invocation. Timeout: None
* Returned Application Errors: RTE_E_ComM_UserRequest_E_MODE_LIMITATION, RTE_E_ComM_UserRequest_E_NOT_OK
*
*********************************************************************************************************************/
/**********************************************************************************************************************
* DO NOT CHANGE THIS COMMENT! << Start of documentation area >> DO NOT CHANGE THIS COMMENT!
* Symbol: RAB_Core0_100us_doc
*********************************************************************************************************************/
/**********************************************************************************************************************
* DO NOT CHANGE THIS COMMENT! << End of documentation area >> DO NOT CHANGE THIS COMMENT!
/
FUNC(void, SWCCore0Basic_Type_CODE) RAB_Core0_100us(void) /* PRQA S 0850 / / MD_MSR_19.8 */
{
/*
* DO NOT CHANGE THIS COMMENT! << Start of runnable implementation >> DO NOT CHANGE THIS COMMENT!
* Symbol: RAB_Core0_100us
*********************************************************************************************************************/
/**********************************************************************************************************************
* DO NOT CHANGE THIS COMMENT! << End of runnable implementation >> DO NOT CHANGE THIS COMMENT!
*********************************************************************************************************************/
}
直接调用: 相当于有一个全局变量,runnable可以直接读写这个变量。
其写法采用一下语法:(指的是全局变量的名字,data指的是局部变量。这些函数都是在runnable中使用的)
Std_ReturnType Rte_Read_<port>_<data> (<DataType> *data)
Std_ReturnType Rte_Write_<port>_<data> (<DataType> data)
缓存调用: 该调用方式相当于先将全局变量复制到一个runnable的局部变量中,然后对局部变量进行操作,最后把这个局部变量赋值到全局变量中。

使用方法:
<DataType> Rte_IRead_<r>_<port>_<data> (void)
void Rte_IWrite_<r>_<port>_<data> (<DataType> data)
队列调用:
1 | //二维向量的遍历,迭代器遍历 |
1 | //二维向量的遍历,数组下表 |
质数定义:指在大于1的自然数中,除了1和该数自身外,无法被其他自然数整除的数(也可定义为只有1与该数本身两个正因数的数)。
根据定义,采用2到n-1中的每一个数去除n,如果不能被整除,则该数为质数。时间复杂度:O(n)。
1 | bool is_prime(int n) |
质数筛选定理: 如果n不能够被不大于根号n的任何质数整除,则n是一个质数。
参考链接:
1 | bool is_prime(int n){ |

