排序算法
基本概念
排序算法是程序设计中最基本的算法,常用的排序算法有十种,可以分为内部排序和外部排序两种类型:
内部排序
- 内部排序是指待排序列完全存放在内存中所进行的排序过程,适合不太大的元素序列。
- 常见的内部排序算法:冒泡排序,快速排序,插入排序,选择排序,希尔排序,堆排序。
外部排序
- 外部排序是针对于极大量数据的排序算法,由于数据无法一次放入内存,算法采用“排序-归并” 策略,首先将部分数据依次读入内存,排序后生成有序的临时文件,在归并阶段将这些临时文件组成较大的有序文件。
- 常见的外部排序算法有归并排序,计数排序,桶排序,基数排序。
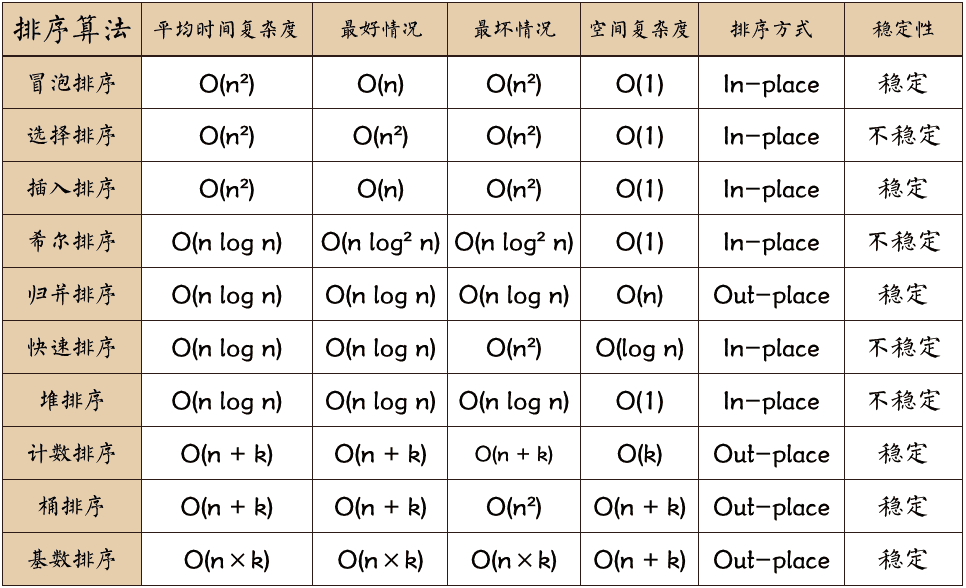
关于排序算法的简单介绍: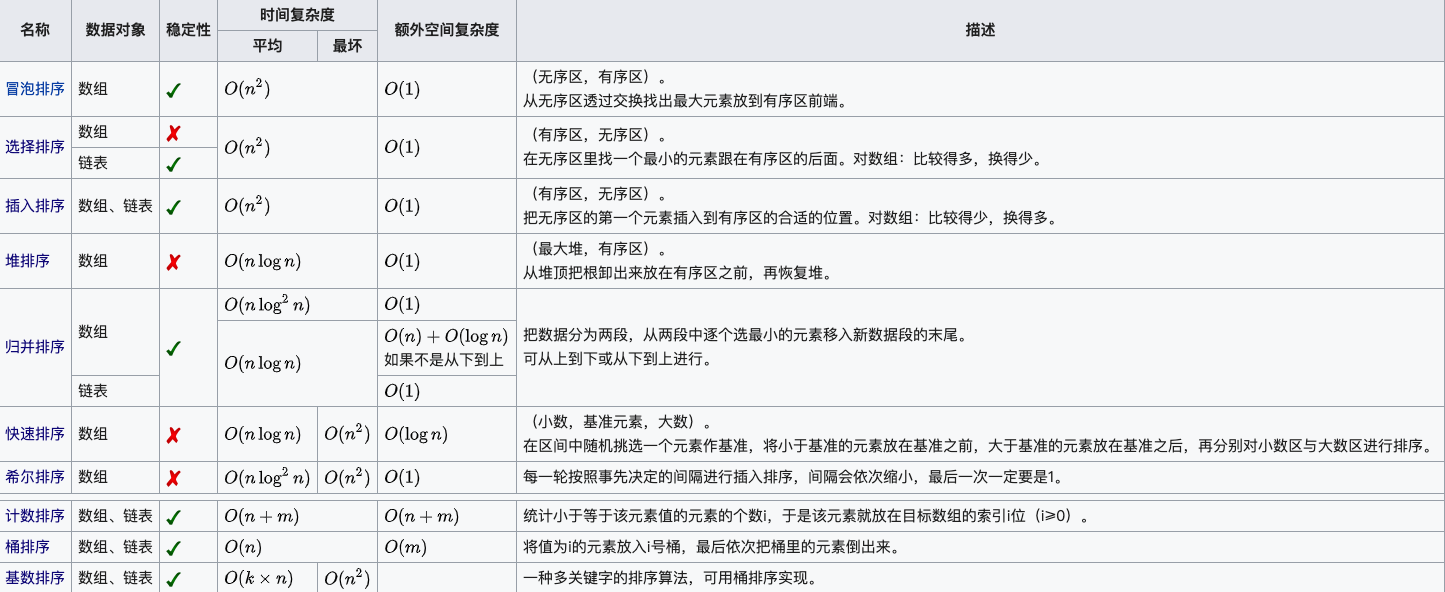
排序算法的稳定性
如果两个具有相同键的对象在输入输出中的顺序与在输入未排序数组中出现的顺序相同,则该排序算法被认为是稳定的。有些排序算法本质上是稳定的,例如插入排序,合并排序,冒泡排序等。而有些排序算法则不是,例如堆排序,快速排序等。
但是,任何给定的不稳定算法都可以修改为稳定。可以使用特定的排序算法来使其稳定,但是通常,可以通过更改键比较操作将本质上不稳定的任何基于比较的排序算法修改为稳定,以便将两个键的比较视为位置。具有相同键的对象的系数。参考文献
冒泡排序
冒泡排序(Bubble Sort)重复遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。 重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
算法步骤:
- 以升序为例,比较相邻两个元素大小,如果第一个元素大于第二个,则交换两个元素,否则不做改变。
- 从数组的第一个元素开始,遍历到数组的倒数第二个元素。
代码实现:
1 | #include <iostream> |
选择排序
选择排序的方法为第一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小(大)元素,然后放到已排序的序列的末尾。 以此类推,直到全部待排序的数据元素的个数为零。 选择排序是不稳定的排序方法。
算法步骤:
- 记录数据中的第一个元素的index
- 遍历数据并与该元素进行比较,如果小于该元素则更新index,完成遍历后交换第一个元素和index所指向的最小值。
- 重复以上步骤直至完成排序。
代码实现:
1 | void selection_sort(vector<int> &num, int len){ |
插入排序
将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)
代码实现:
1 | void intersection_sort(vector<int> &num, int len){ |
希尔排序
希尔排序(Shellsort),也称递减增量排序算法,是插入排序的一种更高效的改进版本。希尔排序是非稳定排序算法。希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位
希尔排序原理的视频介绍:希尔排序

算法实现:
1 | void shell_sort(vector<int> &num, int len){ |
快速排序
快速排序是在实践中最快的已知排序算法,算法的平均运行时间是O(NlogN), 最坏的性能为O(N^2).
算法步骤:
从数列中随机挑出一个元素,称为 “基准”(pivot);
重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
算法实现:
1 |
归并排序
归并排序(Merge sort)是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
作为一种典型的分而治之思想的算法应用,归并排序的实现由两种方法:
- 自上而下的递归(所有递归的方法都可以用迭代重写,所以就有了第 2 种方法);
- 自下而上的迭代;
和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是 O(nlogn) 的时间复杂度。代价是需要额外的内存空间。
算法步骤:
申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列;
设定两个指针,最初位置分别为两个已经排序序列的起始位置;
比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置;
重复步骤 3 直到某一指针达到序列尾;
将另一序列剩下的所有元素直接复制到合并序列尾
参考资料:
[1] 关于排序算法的一点知识——实例和伪代码
[2]
install_url to use ShareThis. Please set it in _config.yml.
